ConvexAvatars
ConvexAvatars models the human head directly with dynamic 3D convex primitives rigged to a FLAME expression model. Surface normals are computed at render time via ray-triangle intersection, giving geometry-grounded normals that enable physically-based relighting.
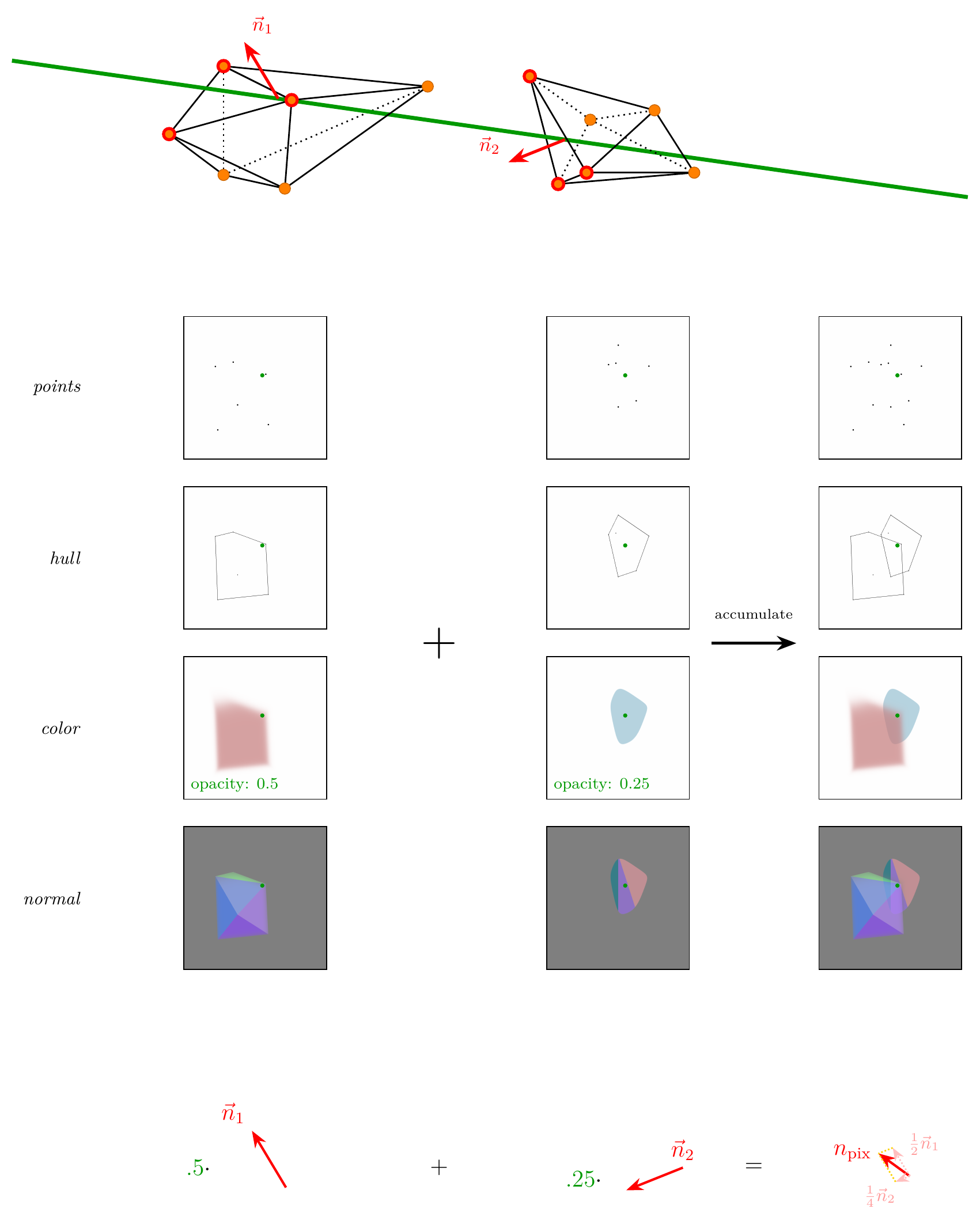
Primitive Normals via Ray-Triangle Intersection
For each pixel, a camera ray is cast and intersected against the convex hull of each contributing primitive. The hit triangle's face normal is accumulated as a weighted sum across primitives, weighted by their opacity. This gives geometry-grounded normals with no view-direction conditioning and with gradients flowing back to the vertex positions during training.
Robust to Limited Training Data
Training on a single expression sequence (SEN-01) instead of the full dataset costs ConvexAvatars only 0.16 dB PSNR, versus 1.20 dB for RGCA and 0.99 dB for BecomingLit. Because normals come from geometry rather than a learned decoder, the network does not need to see a wide distribution of lighting conditions to produce meaningful surface information. This suggests the approach is well-suited for low-data capture settings where multi-view OLAT rigs are unavailable.
| Method | Training | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| RGCA [Sai+24] | Full | 24.79 | 0.8394 | 0.1644 |
| SEN-01 | 23.59 | 0.8022 | 0.1964 | |
| Δ | -1.20 | -0.037 | +0.032 | |
| BecomingLit [SGN25] | Full | 27.10 | 0.8545 | 0.1524 |
| SEN-01 | 26.11 | 0.8363 | 0.1578 | |
| Δ | -0.99 | -0.018 | +0.005 | |
| Ours (ConvexAvatars) | Full | 26.31 | 0.8718 | 0.2133 |
| SEN-01 | 26.15 | 0.8643 | 0.1983 | |
| Δ | -0.16 | -0.008 | -0.015 |
[Sai+24] Saito et al., "Relightable Gaussian Codec Avatars," CVPR 2024. [SGN25] Schmidt, Giebenhain & Niessner, "BecomingLit," NeurIPS 2025.